KL Divergence Explained
Generative Models series: 1. Originally published on Medium.
Every generative model I've studied hits the same point in the loss derivation: KL divergence. It shows up in VAEs explicitly, normalizing flows (NF) arrive at it through maximum likelihood, and flow matching is partly motivated by the problems it causes. Getting it wrong early means re-deriving it from scratch every time a new architecture appears.
Entropy
For a discrete distribution P over outcomes x:
H(P) = -Σ P(x) log(P(x))
The term log(1/P(x)) captures surprise: a rare outcome carries a high surprise value, a likely one carries almost none. Entropy weights each surprise value by how often that outcome occurs under P, then sums. Entropy is the average surprise across the distribution.
A distribution peaked at one outcome has zero entropy; you already know what's coming. A uniform distribution has maximum entropy, with no outcome more expected than any other. KL applies the same accounting across two distributions at once.
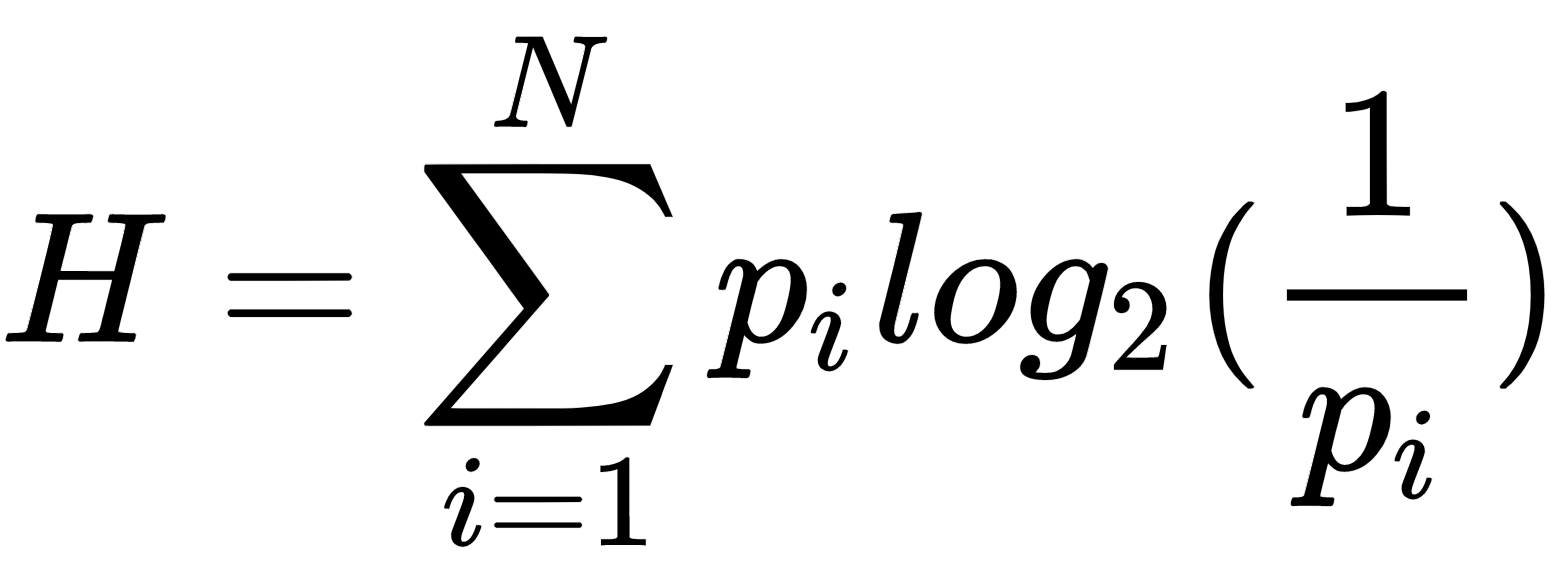
Source: Machine Learning with Swift by Alexander Sosnovshchenko
KL Divergence
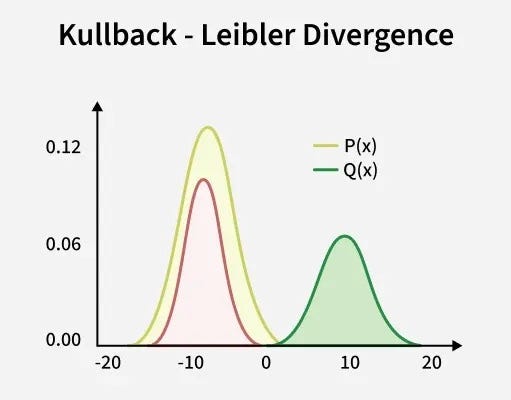
Given two distributions P and Q over the same space:
KL(P ‖ Q) = Σ P(x) log [P(x) / Q(x)]
The log[P(x)/Q(x)] term is the difference in surprise between P's model and Q's model at outcome x. P(x) weights that difference by how often x actually occurs. Summed over all x, KL(P‖Q) is the average extra surprise from using Q's description when P is the true distribution.
When P = Q, all log ratios are zero and KL = 0. When Q assigns low probability to outcomes P considers likely, those log ratios grow without bound. The measure is always non-negative, a result known as Gibbs' inequality.
The asymmetry KL(P‖Q) ≠ KL(Q‖P) matters: each direction penalizes a different kind of failure.
Source: Geeksforgeeks - Kullback Leibler (KL) Divergence
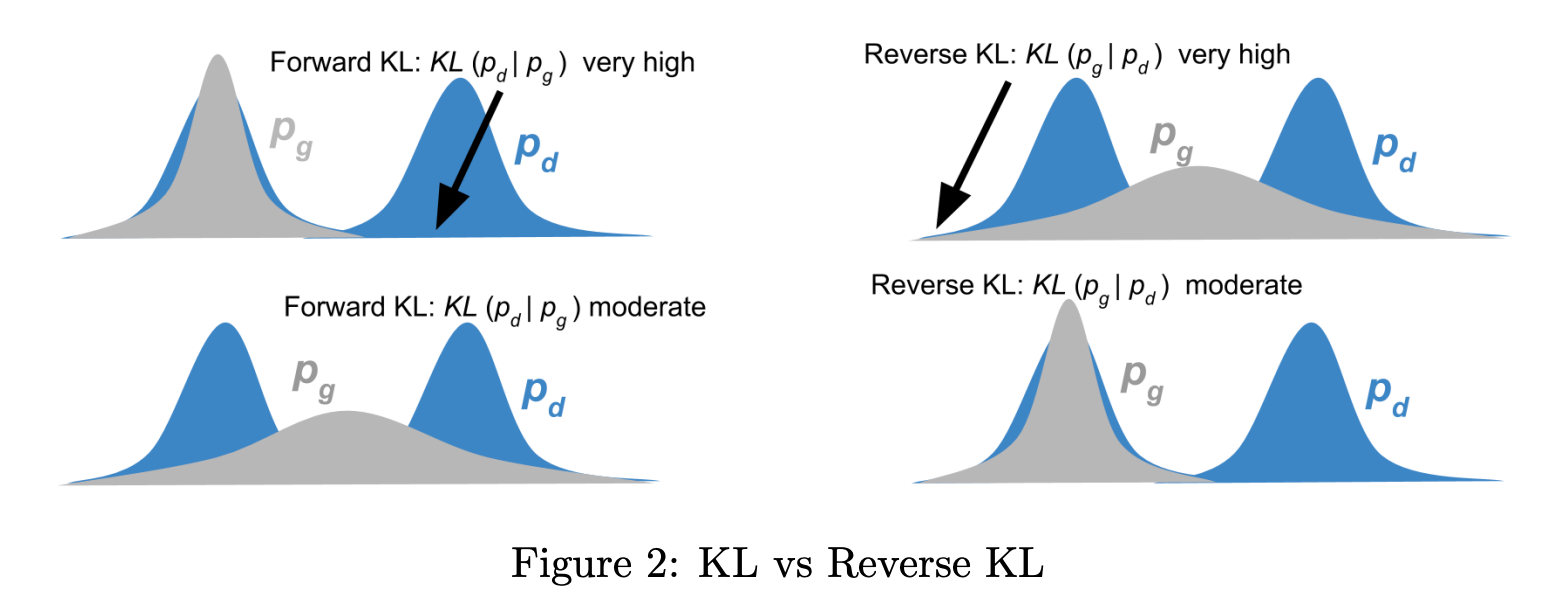
Forward vs Reverse KL
Reverse KL: KL(Q ‖ P)
Q's probabilities do the weighting. Any region where Q has mass but P doesn't incurs a heavy penalty, so Q contracts into P's support. With a multimodal P, Q tends to collapse onto a single mode and ignore the rest, a behavior called mode-seeking.
Reverse KL is the direction minimized in variational inference. Mode collapse in VAE-style training follows directly from this: Q concentrates on the most probable mode and leaves the others uncovered.
Forward KL: KL(P ‖ Q)
P's probabilities do the weighting. The penalty is large wherever P has mass and Q doesn't, so Q is forced to cover every region P occupies. With a multimodal P and a unimodal Q, Q spreads mass across all modes, sometimes landing probability in the gaps where P is actually low. This is mean-seeking or zero-avoiding behavior.
Fitting Q to data from P by maximizing log-likelihood is equivalent to minimizing KL(P‖Q). The two objectives differ by a constant.
Source: Manisha & Gujar (2018) - GAN survey
Why generative models care
A generative model learns Q_θ over data x. Maximizing log-likelihood on samples is equivalent to minimizing KL(P_data ‖ Q_θ) up to a constant, so KL is implicit in the training objective whether written out or not.
The trouble comes with latent variables. Computing the exact likelihood P_data(x) requires integrating over all latent configurations, and that integral is intractable. The next post works through the fix: introduce an approximate distribution Q and optimize a lower bound on log-likelihood instead. That bound is the ELBO, and KL is at the core of its derivation.
References
- Shlens, J. (2014). Notes on Kullback-Leibler Divergence and Likelihood Theory. arXiv:1404.2000v1 [cs.IT]. https://arxiv.org/abs/1404.2000
- Gray, R. M. (2023). Entropy and Information Theory (1st ed., corrected). Stanford University. https://ee.stanford.edu/~gray/it.pdf
- Han, J., Kamber, M., & Pei, J. (2011). Data Mining: Concepts and Techniques (3rd ed., §2.4.8). Morgan Kaufmann. https://hanj.cs.illinois.edu/cs412/bk3/KL-divergence.pdf
- Elton, D. C. Notes on GAN Objective Functions. http://www.moreisdifferent.com/assets/science_notes/notes_on_GAN_objective_functions.pdf
- Manisha, P., & Gujar, S. (2018). Generative Adversarial Networks (GANs): The Progress So Far In Image Generation. arXiv:1804.00140. https://arxiv.org/pdf/1804.00140